
EGG Finance è un CRM verticale per il mondo finanziario. Gestisce dati sensibili, flussi operativi serrati e operatori che non hanno tempo di fare data entry campo per campo. La richiesta è semplice da dire e complessa da realizzare: uno strumento interno (niente giri su servizi terzi) capace di leggere documenti (identità e documenti fiscali come 730, buste paga, codice fiscale) ed estrarre automaticamente le informazioni per pre-compilare le schede del CRM sia in inserimento (operatore davanti alla schermata) sia in bulk (centinaia o migliaia di documenti a colpo). Obiettivo: velocità, accuratezza, tracciabilità. E, soprattutto, privacy by design: i dati non escono dal perimetro EGG.
Nessun documento è “standard”. Le buste paga sembrano uguali finché le metti una accanto all’altra: formati diversi, layout creativi, sezioni che migrano, diciture che cambiano con l’aria. I 730? Stesso film, capitolo nuovo. In mezzo, PDF nativi (ricercabili) alternati a scansioni borderline: storte, sgranate, con timbri sopra i numeri. Il sistema deve riconoscere che cosa ha davanti, scegliere la strategia giusta e non impazzire quando i casi limite bussano alla porta. Il tutto con latenze compatibili con l’uso in back-office e tassi di errore che non costringano gli operatori a rifare il lavoro a mano.
Niente bacchette magiche. Solo R&D metodica, parecchia ingegneria dei dati e un’architettura che cresce per moduli. Abbiamo lavorato a quattro mani col team di EGG Finance, dal primo spike fino a un sistema che oggi è un ensemble ragionato: più modelli, più regole, decision trees a orchestrare il tutto.
Il sistema è scritto per vivere dentro EGG Finance. API interne e job schedulati gestiscono due scenari: real-time assistito in fase di inserimento e bulk ingestion per import massivi. Tutto è idempotente: lo stesso documento non crea doppioni, ma versioni e audit. La pipeline logga ogni passaggio (classificazione, estrazione, validazioni, errori gestiti) per consentire monitoraggio e diagnostica: se una variante di busta paga “nuova” inizia a girare nel mercato, la vediamo dai drift sugli score e interveniamo.
Sul fronte sicurezza: cifratura in transito e a riposo, controllo accessi per ruolo, nessuna chiamata verso l’esterno con PII. Il principio resta quello: tutto in casa.
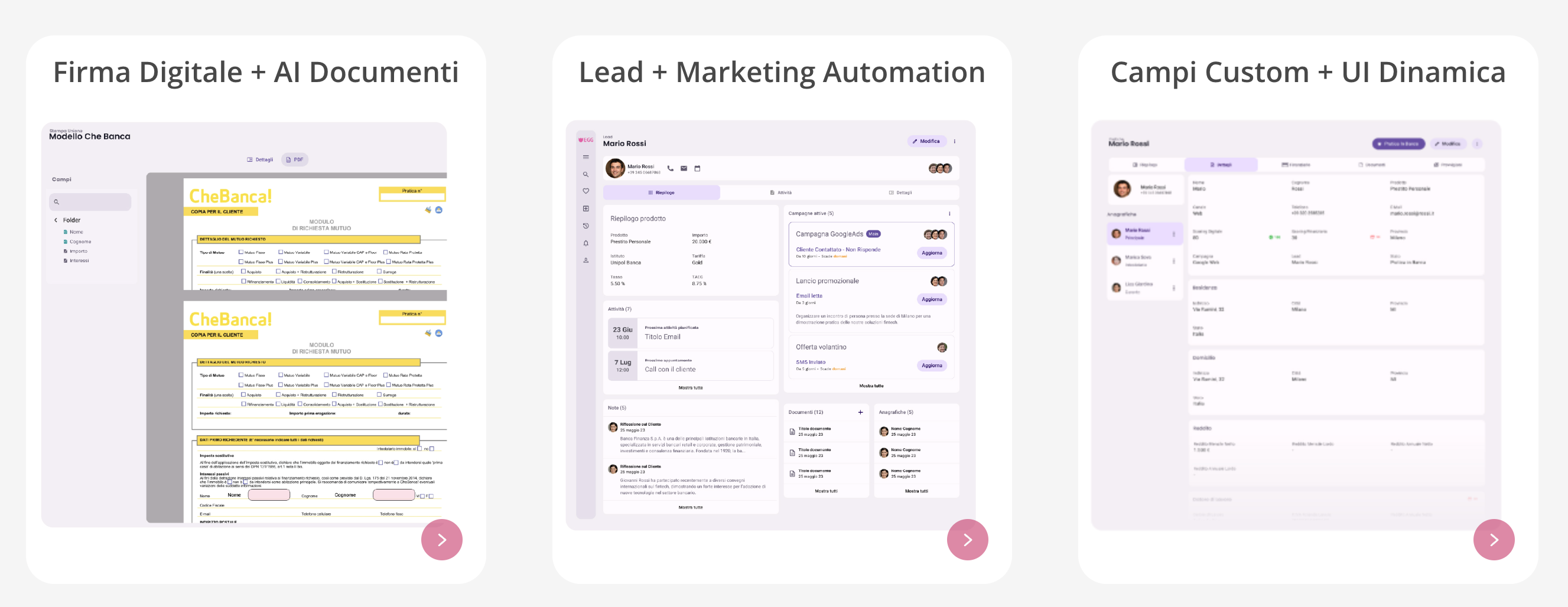
La differenza si nota prima che qualcuno chieda “quanto tempo abbiamo risparmiato?”. Gli operatori non partono più da zero: i campi cruciali arrivano già al loro posto, con un tono di grigio diverso se il sistema è meno sicuro. Meno noia, meno errori di battitura, meno doppie verifiche. Nel bulk sparisce l’incubo del “carica file → torna domani”: l’estrazione gira, logga, e allinea i record in modo tracciabile. Nessun fuoco d’artificio, solo fluidità nell’operativo quotidiano.
Perché i documenti cambiano. Perché la qualità dell’immagine oscilla. Perché i casi limite esistono. Un ensemble ben orchestrato ti permette di adattarti senza stravolgere tutto: aggiungi un estrattore, modifichi un ramo del decision tree, non tocchi il resto. È manutenibile.
Dalla raccolta e normalizzazione dei campioni (anonimizzati) alla definizione delle tassonomie di campo per ogni documento; dalla progettazione dei feature extractor specifici alla costruzione di golden set per i test di regressione; dalla validazione dei punteggi per campo a regole di coerenza inter-documento (quando più file di uno stesso cliente devono raccontare la stessa storia). Abbiamo iterato su precisione/recall a livello di campo (non solo “il documento è buono?” ma “questo campo è corretto?”), e messo in piedi metriche che gli stakeholder capiscono: quanto lavoro in meno per l’operatore, quante correzioni residuali, dove intervenire per guadagnare il prossimo punto percentuale.
Un sistema in produzione che riconosce il tipo di documento, seleziona la tattica migliore, estrae i dati e popola le schede di EGG Finance sia in assistito sia in bulk, con controlli di qualità, log e una strada chiara per nuove famiglie di documenti. Non promettiamo “zero errori” (chi lo fa, mente); promettiamo una piattaforma che migliora nel tempo, non rompe i flussi e rispetta i dati.
Tre direzioni naturali:
EGG Finance aveva bisogno di “far parlare” i documenti dentro il proprio perimetro. Abbiamo costruito un sistema che ascolta, capisce, estrae e compila.

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.








